Je préviens avant, je ne suis ni épidémiologiste ou quoi que ce soit donc ce que je dis n'engage que moi et j'interprete selon mes pensées.
Tout d'abord nous allons commencer par utiliser les données mises à disposition par le gouvernement. .
Analyse globale
Commencons par regarder globalement l'évolution des personnes hospitalisées pour Covid. Pour cela on va charger notre fichier CSV avec la librairie Pandas puis utiliser Seaborn
pour mettre tout ca en graphique.
import matplotlib.pyplot as plt
import pandas as pd
pd.plotting.register_matplotlib_converters()
import seaborn as sns
# Fichier de data sur data.gouv.fr
file = "sursaud-covid19-quotidien-2020-04-30-19h00-France.csv"
# On va utiliser Pandas pour traiter ca et on va selectionner de maniere differenciee chaque age (y a plus propre mais c'est plus lisible je trouve)
txt = pd.read_csv(file)
# On choisi tous les cas quels que soit leur age
data = txt[txt['sursaud_cl_age_corona'] == '0']
# On va reduire l'index de chaque en divisant par 6 vu qu'il y a une donnee toute les 6 lignes
data.index = data.index.map(lambda x: int(x / 6))
plt.figure(figsize=(24, 10))
# Vous pouvez commentez le moins visuel des 2 selon vos gouts
sns.barplot(x=data.index, y=data['nbre_hospit_corona'], label="Nb hospit corona")
sns.lineplot(data=data['nbre_hospit_corona'], label="Nb hospit corona")
plt.xlabel('Nb jour')
plt.show()
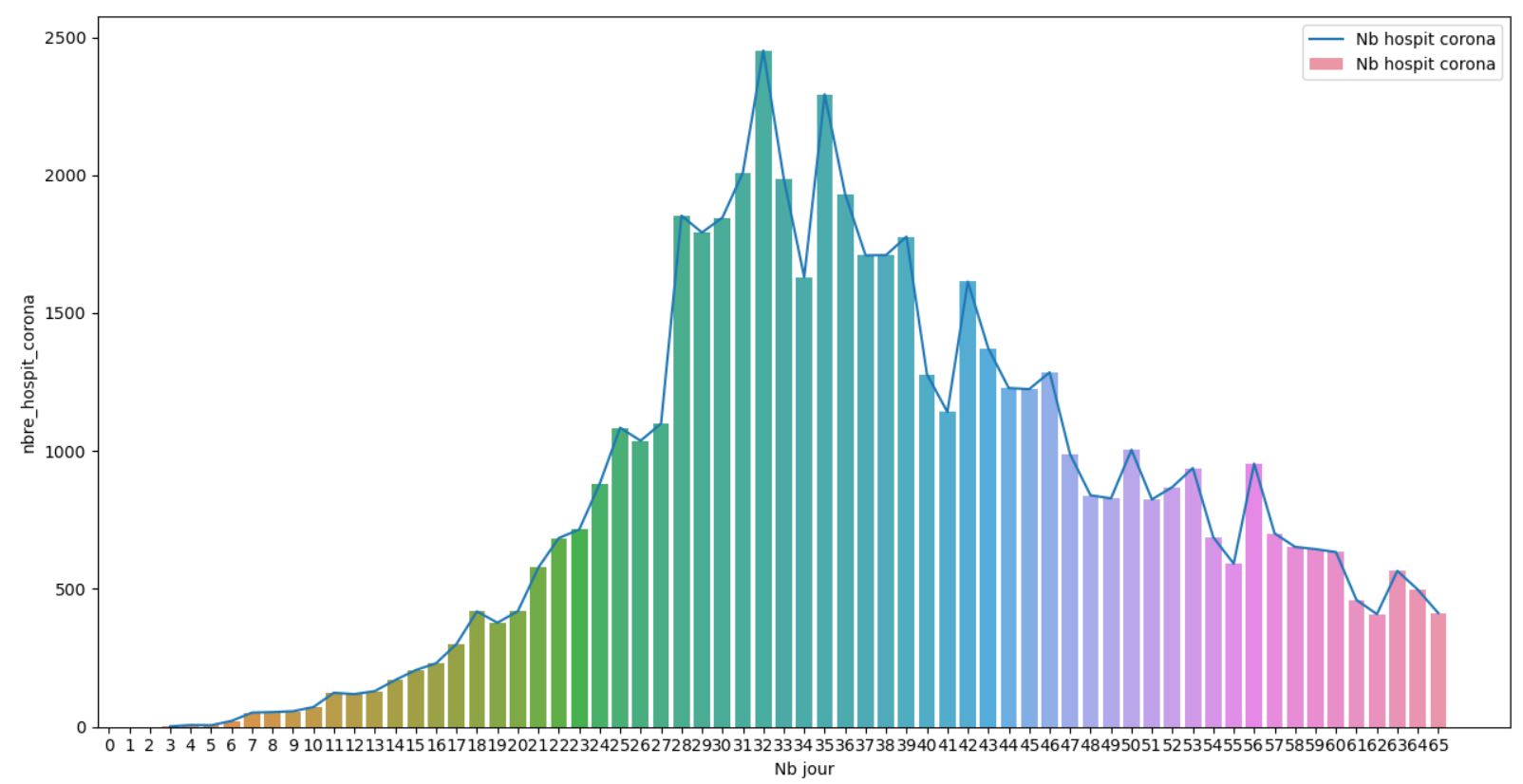
Le confinement a débuté le 14 Mars, ce qui correspond au jour 19 ici. On voit que le pic est arrivé Jour 32, donc le 27 Mars ce qui semble cohérent au 6 / 7 jour d'incubation avant les 1ers symptomes puis ici des aggravations entrainant le pic. On voit bien que cette phase de courbe est exponentielle et qu'attendre plus aurait explosé le système hospitalier. On voit ici qu'il a été efficace car pas de butée sur plusieurs jours à un meme niveau.
On observe une décroissance des hospitalisations qui semble un peu ralentir mais on se rapproche de la limite basse qui va etre compliquée à réduire sans nouvelle mesure sanitaire sachant que la fin du confinement approche.
Analyse par age
Regardons maintenant cette courbe mais par age. Les données fournies nous permettent d'analyser 5 tranches d'ages :
- les moins de 15ans
- de 15 à 44ans
- de 45 à 64ans
- de 65 à 74ans
- + de 74ans
import matplotlib.pyplot as plt
import pandas as pd
pd.plotting.register_matplotlib_converters()
import seaborn as sns
# Fichier de data sur data.gouv.fr
file = "sursaud-covid19-quotidien-2020-04-30-19h00-France.csv"
# On va utiliser Pandas pour traiter ca et on va selectionner de maniere differenciee chaque age (y a plus propre mais c'est plus lisible je trouve)
txt = pd.read_csv(file)
data = txt[txt['sursaud_cl_age_corona'] == '0']
data15 = txt[txt['sursaud_cl_age_corona'] == 'A']
data44 = txt[txt['sursaud_cl_age_corona'] == 'B']
data64 = txt[txt['sursaud_cl_age_corona'] == 'C']
data74 = txt[txt['sursaud_cl_age_corona'] == 'D']
data99 = txt[txt['sursaud_cl_age_corona'] == 'E']
# On va reduire l'index de chaque en divisant par 6 vu qu'il y a une donnee toute les 6 lignes
data.index = data.index.map(lambda x: int(x / 6))
data15.index = data15.index.map(lambda x: int(x / 6))
data44.index = data44.index.map(lambda x: int(x / 6))
data64.index = data64.index.map(lambda x: int(x / 6))
data74.index = data74.index.map(lambda x: int(x / 6))
data99.index = data99.index.map(lambda x: int(x / 6))
plt.figure(figsize=(24, 10))
# Evolution des hospitalisations pour COVID par age
# sns.lineplot(data=data, x=data.index, y=data['nbre_hospit_corona'], hue='sursaud_cl_age_corona', label=["Nb hospitalisation corona"]) # Fait tout en 1 ligne mais reste a voir les labels
sns.lineplot(data=data['nbre_hospit_corona'], label="Nb hospitalisation corona")
sns.lineplot(data=data15['nbre_hospit_corona'], label="Nb hospitalisation corona - 15ans")
sns.lineplot(data=data44['nbre_hospit_corona'], label="Nb hospitalisation corona 15 - 44ans")
sns.lineplot(data=data64['nbre_hospit_corona'], label="Nb hospitalisation corona 45 - 64ans")
sns.lineplot(data=data74['nbre_hospit_corona'], label="Nb hospitalisation corona 65 - 74ans")
sns.lineplot(data=data99['nbre_hospit_corona'], label="Nb hospitalisation corona + 74ans")
plt.xlabel('Date')
plt.show()
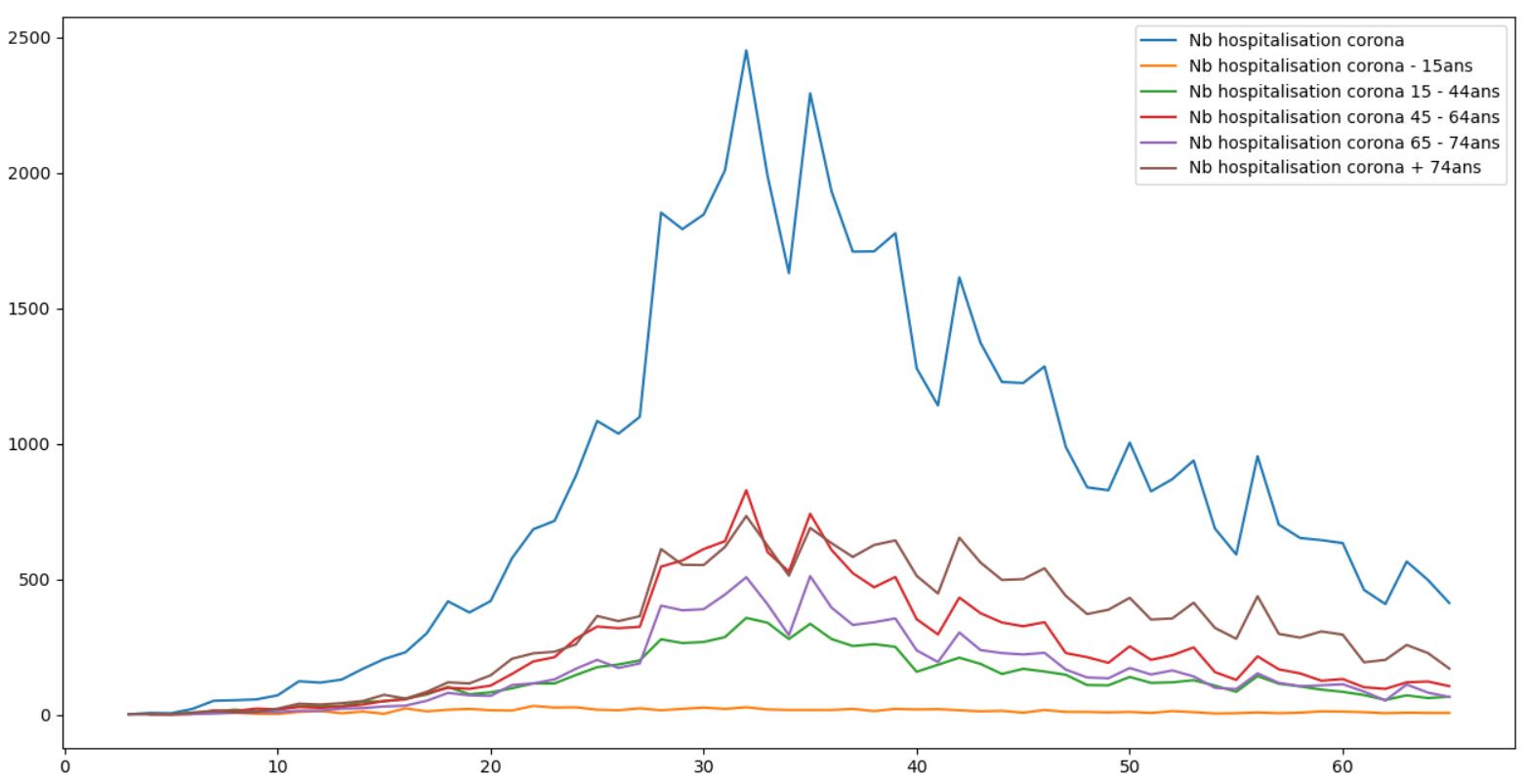
Ici on voit bien que les cas de jeunes est très faible. Pour le reste, à partir de 15ans je reste moins catégorique. L'age ne semble pas vraiment impacter le taux d'hospitalisation.
Celui-ci semble plus lié à un facteur autre, telle une comorbidité qui peut etre diverse selon l'age. Bien sur cela est vrai pour la tranche 15-74ans. Après on voit quand meme bien que cette population est bien plus atteinte et fragile.
On entend très souvent que le Covid est une maladie qui impacte les plus agés. C'est peut etre vrai pour l'aspect léthal mais pour ce qui est de l'hospitalisation, je serai moins catégorique.
Analyse par sexe
Récupérons maintenant les données pour afficher toujours ce taux d'hospitalisation mais cette fois par sexe pour voir s'il y a une différence.
import matplotlib.pyplot as plt
import pandas as pd
pd.plotting.register_matplotlib_converters()
import seaborn as sns
# Fichier de data sur data.gouv.fr
file = "sursaud-covid19-quotidien-2020-04-30-19h00-France.csv"
# On va utiliser Pandas pour traiter ca et on va selectionner de maniere differenciee chaque age (y a plus propre mais c'est plus lisible je trouve)
txt = pd.read_csv(file)
data = txt[txt['sursaud_cl_age_corona'] == '0']
# On va reduire l'index de chaque en divisant par 6 vu qu'il y a une donnee toute les 6 lignes
data.index = data.index.map(lambda x: int(x / 6))
plt.figure(figsize=(24, 10))
# Evolution des hospitalisations pour COVID par sexe
sns.lineplot(data=data['nbre_hospit_corona'], label="Nb hospitalisation corona")
sns.lineplot(data=data['nbre_hospit_corona_h'], label="Nb hospitalisation corona homme")
sns.lineplot(data=data['nbre_hospit_corona_f'], label="Nb hospitalisation corona femme")
plt.xlabel('Date')
plt.show()
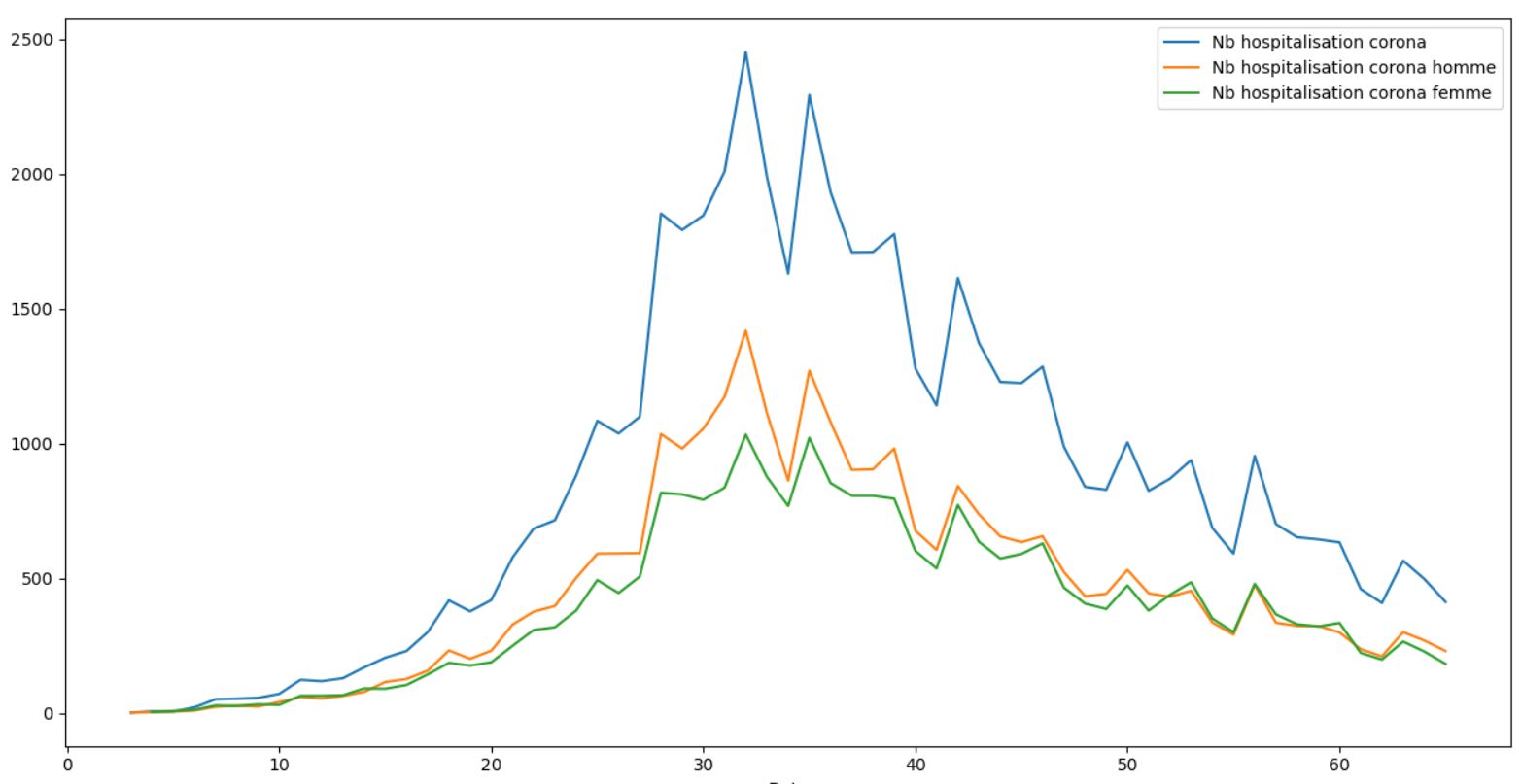
On observe principalement une différence au moment du pic. Une fois que celui-ci est passé, les courbes Hommes / Femmes finissent par s'entrecroiser régulièrement montrant qu'au final il n'y a pas vraiment de différence d'impact. Le pic préalable pourrait etre du au fait par exemple que les hommes ont tendance à avoir plus de contacts physiques avec le serrage de main ou autre. Une fois les gestes barrières et le confinement mis en place, cette différenciation disparait alors.
Analyse des taux de nouveaux cas / guéris et décès
Nous allons maintenant utiliser les données du CSSE de l'Universite de John Hopkins
afin de récupérer les données sur les nouveaux cas / guéris et décès en France et comparer cela avec la Corée du Sud pour tenter de prédire une date de fin de confinement.
Nous allons afficher cela via barplot() en stackant les 3 données.Pour cela on va concaténer les 3 dataframes puis créer une colonne qui va soustraire les décès et cas guéris aux cas détectés
afin d'avoir le nombre réel de cas actuel en France.
import matplotlib.pyplot as plt
import pandas as pd
pd.plotting.register_matplotlib_converters()
import seaborn as sns
import warnings # `do not disturbe` mode
warnings.filterwarnings('ignore')
fileconfirmed = "confirmed_global_29-04.csv"
filedeath = "deaths_global_29-04.csv"
filerecovered = "recovered_global_29-04.csv"
# On charge le fichier via Pandas
data = pd.read_csv(fileconfirmed)
# On recupere les donnees de la France
data['Province/State'] = data['Province/State'].fillna(0)
dataconfirmed = data[((data['Country/Region'] == 'France') & (data['Province/State'] == 0))]
data = pd.read_csv(filedeath)
data['Province/State'] = data['Province/State'].fillna(0)
datadeaths = data[((data['Country/Region'] == 'France') & (data['Province/State'] == 0))]
data = pd.read_csv(filerecovered)
data['Province/State'] = data['Province/State'].fillna(0)
datarecovered = data[((data['Country/Region'] == 'France') & (data['Province/State'] == 0))]
# On supprime les colonnes qui ne nous servent pas
dataconfirmed = dataconfirmed.drop(columns=['Province/State', 'Country/Region', 'Lat', 'Long'])
# On va inverser les colonnes et lignes pour pouvoir analyser ligne par ligne
dataconfirmed = pd.np.transpose(dataconfirmed)
cols = dataconfirmed.columns
dataconfirmed = dataconfirmed.rename(columns={cols[0]: 'Confirmed'})
# On refait de meme pour les deces et les gueris
datadeaths = datadeaths.drop(columns=['Province/State', 'Country/Region', 'Lat', 'Long'])
datadeaths = pd.np.transpose(datadeaths)
cols = datadeaths.columns
datadeaths = datadeaths.rename(columns={cols[0]: 'Deaths'})
datarecovered = datarecovered.drop(columns=['Province/State', 'Country/Region', 'Lat', 'Long'])
datarecovered = pd.np.transpose(datarecovered)
cols = datarecovered.columns
datarecovered = datarecovered.rename(columns={cols[0]: 'Recovered'})
# On concatene les Dataframes
datacomplete = pd.concat([dataconfirmed, datadeaths, datarecovered], axis=1, sort=False)
# On cree une colone au Dataframe de cas reels actuels
datacomplete['Restant'] = datacomplete['Confirmed'] - datacomplete['Recovered'] - datacomplete['Deaths']
# On n'affiche du 45e jour a la fin pour supprimer les 1ers jours quasi nuls
datacomplete = datacomplete[45:]
# On affiche cette fois en barplot()
sns.barplot(data=datacomplete, x=datacomplete.index, y=datacomplete['Confirmed'], label="Nb confirme", color="blue")
sns.barplot(data=datacomplete, x=datacomplete.index, y=datacomplete['Recovered'], label="Nb gueris", color="green")
sns.barplot(data=datacomplete, x=datacomplete.index, y=datacomplete['Deaths'], label="Nb morts", color="black")
plt.xlabel('Date')
plt.show()
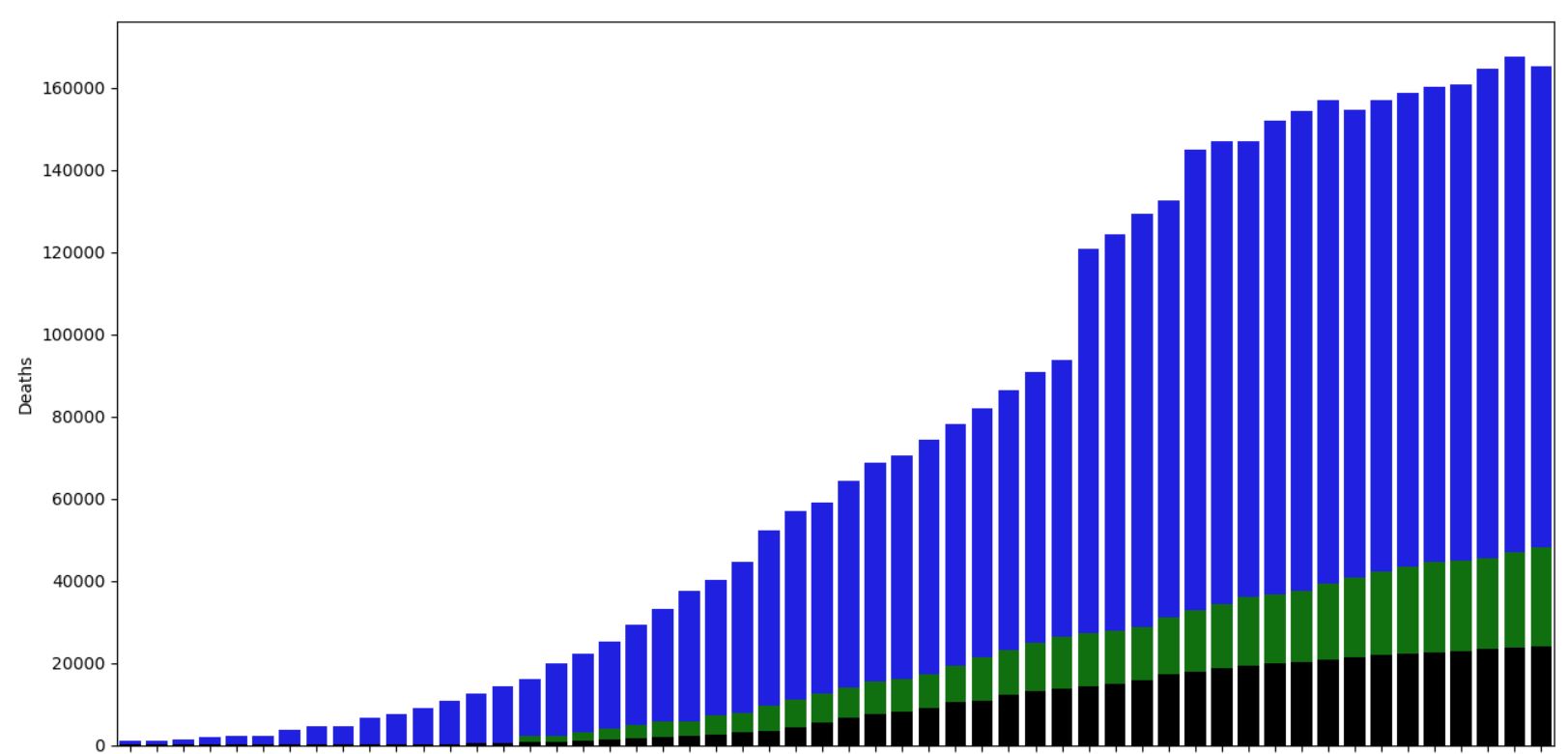
Rien à dire de particulier. La courbe des décès semble s'aplanir ce qui est bon signe. Celle des guéris légèrement aussi, mais en comparant avec la Corée du Sud, on constate que c'est pareil donc cela semble normal.
Nous allons ensuite afficher le nombre de cas réels actuels. Pour cela nous allons concaténer les 3 dataframes puis créer une colonne qui va soustraire les décès et cas guéris aux cas détectés
afin d'avoir le nombre réel de cas actuel en France.
import matplotlib.pyplot as plt
import pandas as pd
pd.plotting.register_matplotlib_converters()
import seaborn as sns
import warnings # `do not disturbe` mode
warnings.filterwarnings('ignore')
fileconfirmed = "confirmed_global_29-04.csv"
filedeath = "deaths_global_29-04.csv"
filerecovered = "recovered_global_29-04.csv"
# On charge le fichier via Pandas
data = pd.read_csv(fileconfirmed)
# On recupere les donnees de la France
data['Province/State'] = data['Province/State'].fillna(0)
dataconfirmed = data[((data['Country/Region'] == 'France') & (data['Province/State'] == 0))]
data = pd.read_csv(filedeath)
data['Province/State'] = data['Province/State'].fillna(0)
datadeaths = data[((data['Country/Region'] == 'France') & (data['Province/State'] == 0))]
data = pd.read_csv(filerecovered)
data['Province/State'] = data['Province/State'].fillna(0)
datarecovered = data[((data['Country/Region'] == 'France') & (data['Province/State'] == 0))]
# On supprime les colonnes qui ne nous servent pas
dataconfirmed = dataconfirmed.drop(columns=['Province/State', 'Country/Region', 'Lat', 'Long'])
# On va inverser les colonnes et lignes pour pouvoir analyser ligne par ligne
dataconfirmed = pd.np.transpose(dataconfirmed)
cols = dataconfirmed.columns
dataconfirmed = dataconfirmed.rename(columns={cols[0]: 'Confirmed'})
# On refait de meme pour les deces et les guéris
datadeaths = datadeaths.drop(columns=['Province/State', 'Country/Region', 'Lat', 'Long'])
datadeaths = pd.np.transpose(datadeaths)
cols = datadeaths.columns
datadeaths = datadeaths.rename(columns={cols[0]: 'Deaths'})
datarecovered = datarecovered.drop(columns=['Province/State', 'Country/Region', 'Lat', 'Long'])
datarecovered = pd.np.transpose(datarecovered)
cols = datarecovered.columns
datarecovered = datarecovered.rename(columns={cols[0]: 'Recovered'})
# On concatene les Dataframes
datacomplete = pd.concat([dataconfirmed, datadeaths, datarecovered], axis=1, sort=False)
# On cree une colone au Dataframe de cas reels actuels
datacomplete['Restant'] = datacomplete['Confirmed'] - datacomplete['Recovered'] - datacomplete['Deaths']
# On n'affiche du 45e jour a la fin pour supprimer les 1ers jours quasi nuls
datacomplete = datacomplete[45:]
# On affiche cette fois en barplot() les cas reels
sns.barplot(data=datacomplete, x=datacomplete.index, y=datacomplete['Restant'], label="Nb confirme", color="blue")
plt.xlabel('Date')
plt.show()
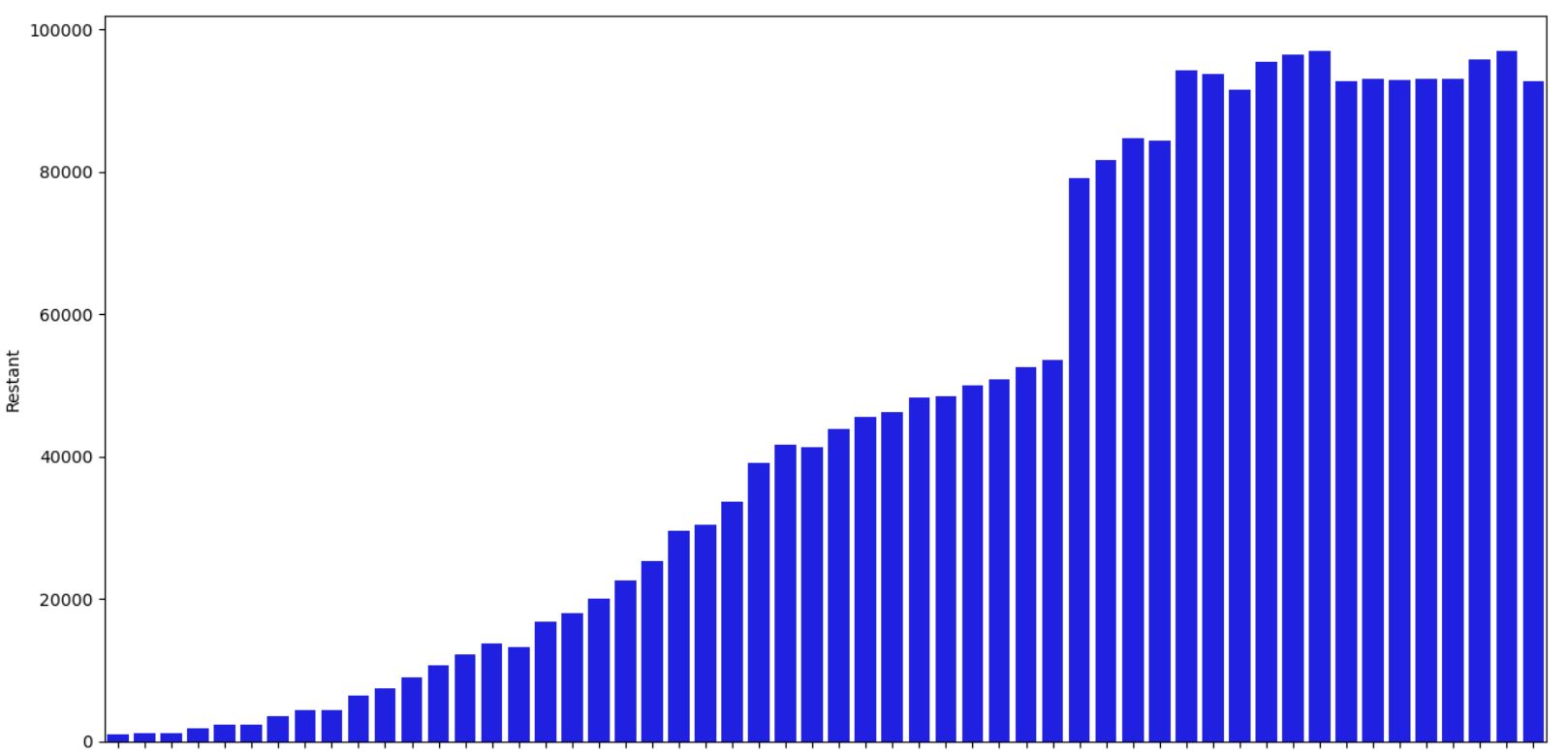
On constate que l'on est sur un plateau montrant une stabilisation de la situation mais pas encore un changement de tendance à la baisse, ce qui pourrait etre un critère évident avant d'envisager un déconfinement. Y a du mieux mais cela ne semble pas suffisant. Il reste 1 semaine pour donc retourner cette tendance.
Comparaison France / Corée du Sud
Pour imaginer le fonctionnement d'un modèle, le mieux reste d'en avoir un qui s'est déjà produit pour ensuite faire des prédictions sur l'actuel. Le Covid-19 est une maladie récente
et du coup pour comparer j'ai décidé arbitrairement de prendre la Corée du Sud. Certes la Corée n'a pas choisie notre méthode mais elle est sur une bonne dynamique de fin d'épidémie.
Pour information pour ceux qui n'ont pas suivi leur méthode, ils n'ont pas confiné mais ont imposé drastiquement la mise en place de gestes barrières comme les masques, de tester massivement
et de mettre en place un système via smartphone de suivi et tracabilité des malades pour détecter tous les cas à risque au plus vite.
Ici je décide donc d'afficher la France et la Corée du Sud en multipliant volontairement les données de la Corée pour avoir une taille visuelle à peu pret semblable à la France.
# -*- coding: utf-8 -*-
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import warnings # `do not disturbe` mode
warnings.filterwarnings('ignore')
# Les DATA
fileconfirmed = "confirmed_global_29-04.csv"
filedeath = "deaths_global_29-04.csv"
filerecovered = "recovered_global_29-04.csv"
# On Cree le Dataframe en recuperant la France et la Coree du Sud qui servira de comparaison
data = pd.read_csv(fileconfirmed)
data['Province/State'] = data['Province/State'].fillna(0)
dataconfirmed = data[(((data['Country/Region'] == 'France') | (data['Country/Region'] == 'Korea, South')) & (
data['Province/State'] == 0))]
data = pd.read_csv(filedeath)
data['Province/State'] = data['Province/State'].fillna(0)
datadeaths = data[(((data['Country/Region'] == 'France') | (data['Country/Region'] == 'Korea, South')) & (
data['Province/State'] == 0))]
data = pd.read_csv(filerecovered)
data['Province/State'] = data['Province/State'].fillna(0)
datarecovered = data[(((data['Country/Region'] == 'France') | (data['Country/Region'] == 'Korea, South')) & (
data['Province/State'] == 0))]
# Au vu du format de la Time Serie, on va transformer les colonnes en ligne
cols = dataconfirmed.columns
dataconfirmed = dataconfirmed.drop(columns=['Province/State', 'Country/Region', 'Lat', 'Long'])
dataconfirmed = pd.np.transpose(dataconfirmed)
cols = dataconfirmed.columns
dataconfirmed = dataconfirmed.rename(columns={cols[0]: 'Confirmed France', cols[1]: 'Confirmed Coree'})
datadeaths = datadeaths.drop(columns=['Province/State', 'Country/Region', 'Lat', 'Long'])
datadeaths = pd.np.transpose(datadeaths)
cols = datadeaths.columns
datadeaths = datadeaths.rename(columns={cols[0]: 'Deaths France', cols[1]: 'Deaths Coree'})
datarecovered = datarecovered.drop(columns=['Province/State', 'Country/Region', 'Lat', 'Long'])
datarecovered = pd.np.transpose(datarecovered)
cols = datarecovered.columns
datarecovered = datarecovered.rename(columns={cols[0]: 'Recovered France', cols[1]: 'Recovered Coree'})
# On concatène les Dataframe pour n'en faire qu'un
datacomplete = pd.concat([dataconfirmed, datadeaths, datarecovered], axis=1, sort=False)
# On cree une colone au Dataframe de cas reels actuels
datacomplete['Restant France'] = datacomplete['Confirmed France'] - datacomplete['Recovered France'] - datacomplete[
'Deaths France']
datacomplete['Restant Coree'] = datacomplete['Confirmed Coree'] - datacomplete['Recovered Coree'] - datacomplete[
'Deaths Coree']
# On va renommer les dates pour etre au format Pandas (pas utile ici mais vous saurez comment modifier les valeurs des lignes
def formatDate(row):
dates = row
datesplit = dates.split('/')
row = "2020-" + str(datesplit[0]) + "-" + str(datesplit[1])
return row
datacomplete.index.names = ['Date']
datacomplete = datacomplete.reset_index()
datacomplete['Date'] = datacomplete['Date'].apply(formatDate)
# On affiche les 2 courbes des pays, en bleu la France et en rouge la Coree
plt.figure(figsize=(24, 10))
sns.lineplot(data=datacomplete, x=datacomplete.index, y=datacomplete['Restant France'], label="Nb confirme France",
color="blue")
sns.lineplot(data=datacomplete, x=datacomplete.index, y=datacomplete['Restant Coree'] * 12, label="Nb confirme Coree",
color="red")
plt.show()
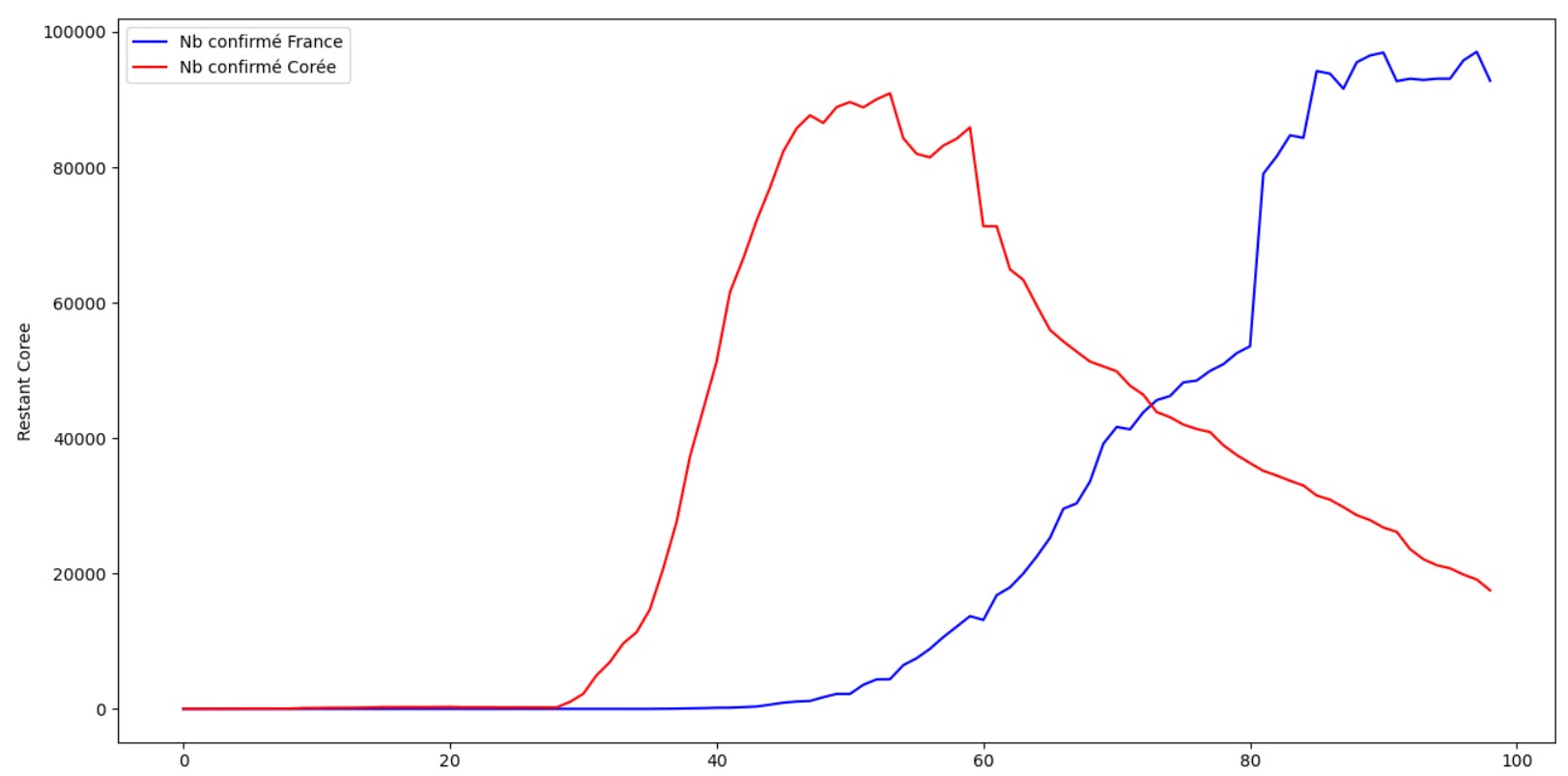
On voit donc bien le retournement de tendance de la Corée qu'il nous reste à amorcer en France pour ensuite attaquer une réelle baisse de l'épidémie.
Prédiction de Time Series
On voit qu'en 46 jours depuis le début de la baisse en Corée, celle-ci à diminuer de 65% son nombre de cas. Par ailleurs on voit qu'on obtient une tendance actuelle assez
linéaire. L'objectif va donc etre de récupérer le début de cette tendance baissière et d'appliquer un modèle de prédiction autant de fois que nécessaire pour arriver à 0 cas en Corée.
Pour cela nous allons utiliser le modèle ARIMA (Autoregressive Integrated Moving Average) qui mélange de l'Autorégression et les moyennes mobiles avec une phase de préprocessing
appelé Intégration.
# -*- coding: utf-8 -*-
import pandas as pd
import matplotlib.pyplot as plt
from statsmodels.tsa.arima_model import ARIMA
import warnings # `do not disturbe` mode
warnings.filterwarnings('ignore')
# Les DATA
fileconfirmed = "confirmed_global_29-04.csv"
filedeath = "deaths_global_29-04.csv"
filerecovered = "recovered_global_29-04.csv"
# Je repars du meme code precedent meme s'il pourrait etre allege
# On cree le Dataframe en recuperant la France et la Coree du Sud qui servira de comparaison
data = pd.read_csv(fileconfirmed)
data['Province/State'] = data['Province/State'].fillna(0)
dataconfirmed = data[(((data['Country/Region'] == 'France') | (data['Country/Region'] == 'Korea, South')) & (
data['Province/State'] == 0))]
data = pd.read_csv(filedeath)
data['Province/State'] = data['Province/State'].fillna(0)
datadeaths = data[(((data['Country/Region'] == 'France') | (data['Country/Region'] == 'Korea, South')) & (
data['Province/State'] == 0))]
data = pd.read_csv(filerecovered)
data['Province/State'] = data['Province/State'].fillna(0)
datarecovered = data[(((data['Country/Region'] == 'France') | (data['Country/Region'] == 'Korea, South')) & (
data['Province/State'] == 0))]
# Au vu du format de la Time Serie, on va transformer les colonnes en ligne
cols = dataconfirmed.columns
dataconfirmed = dataconfirmed.drop(columns=['Province/State', 'Country/Region', 'Lat', 'Long'])
dataconfirmed = pd.np.transpose(dataconfirmed)
cols = dataconfirmed.columns
dataconfirmed = dataconfirmed.rename(columns={cols[0]: 'Confirmed France', cols[1]: 'Confirmed Coree'})
datadeaths = datadeaths.drop(columns=['Province/State', 'Country/Region', 'Lat', 'Long'])
datadeaths = pd.np.transpose(datadeaths)
cols = datadeaths.columns
datadeaths = datadeaths.rename(columns={cols[0]: 'Deaths France', cols[1]: 'Deaths Coree'})
datarecovered = datarecovered.drop(columns=['Province/State', 'Country/Region', 'Lat', 'Long'])
datarecovered = pd.np.transpose(datarecovered)
cols = datarecovered.columns
datarecovered = datarecovered.rename(columns={cols[0]: 'Recovered France', cols[1]: 'Recovered Coree'})
# On concatene les Dataframe pour n'en faire qu'un
datacomplete = pd.concat([dataconfirmed, datadeaths, datarecovered], axis=1, sort=False)
datacomplete['Restant France'] = datacomplete['Confirmed France'] - datacomplete['Recovered France'] - datacomplete[
'Deaths France']
datacomplete['Restant Coree'] = datacomplete['Confirmed Coree'] - datacomplete['Recovered Coree'] - datacomplete[
'Deaths Coree']
datacomplete = datacomplete.reset_index()
# La prediction Time Series prend une serie en entree, ici les donnees de la Coree.
data = datacomplete['Restant Coree']
data = data[66:]
# Nous allons faire une boucle qui va appeler le modele ARIMA pour faire une prediction, puis ajouter celle-ci et relancer la prediction 30fois pour avoir 30jours de prediction
for a in range(1,30):
model = ARIMA(data, order=(1, 1, 1))
model_fit = model.fit(disp=False)
yhat = model_fit.predict(len(data), len(data), typ='levels')
data = data.append(yhat)
# On affiche la prediction pour voir quand elle passe le 0
print(yhat)
plt.figure(figsize=(24, 10))
# On affiche le tout avec matplotlib cette fois
plt.plot(data.index, data, 'r-', label='Prediction')
plt.show()
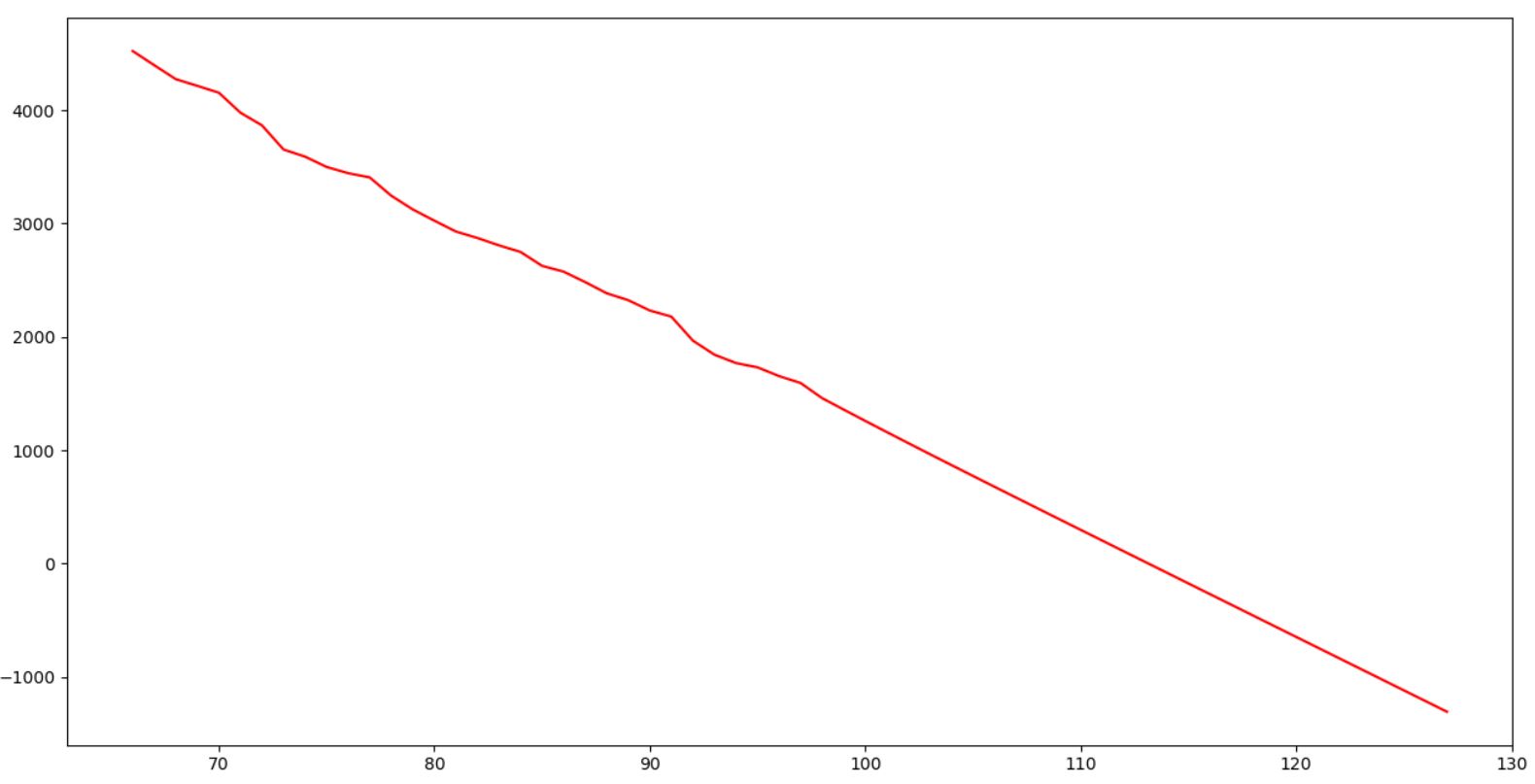
Et voilà, on obtient une droite de prédiction et on constate qu'elle passe les 0 au bout de 16 jours (voir dans les logs affichés par le print(yhat)). La cassure est survenue au 60e jour et nous en sommes au 98e jour.
Nous arrivons donc à une fin des cas de Covid-19 en Corée approximativement au bout de 54 jours après le retournement de tendance (autour du 18 Mai donc pour la Corée).
Nous pouvons donc espérer au mieux, à mon avis, si la rupture est effective au 11 mai, à une fin de crise Covid-19 en France au 04 Juillet.
Conclusion :
La modélisation est un élément très intéressant afin de constater ce que les chiffres présentent afin d'affirmer ou infirmer des hypothèses. La prédiction permet également
de se projeter mais rester sujette à énormément de facteurs externes qui la rende peu fiable dans le cas présent mais peut devenir très robuste dans des cas avec plus
d'information et des tendances saisonnières. Dans le cas présent, la méthode de traitement de la France est bien plus laxiste que celle de la Corée du Sud donc la date annoncée
me parait ultra optimiste mais l'avenir nous le dira :)
Have fun !